Swift 5.0.x String Performance
Turns out, in Swift 5.0.x, String(utf8String:) and String(bytes:encoding:) are not “optimised” compared to String(validatingUTF8:).
Which String initializer are you using, specifically?
— David Smith (@Catfish_Man) May 16, 2019
String(utf8String:) is a Foundation extension and looking at the commit history, it wasn’t optimized to avoid bridging until 5.1 (commit a088e1322495).
String(validatingUTF8:) should be a ton faster in 5.0.x.
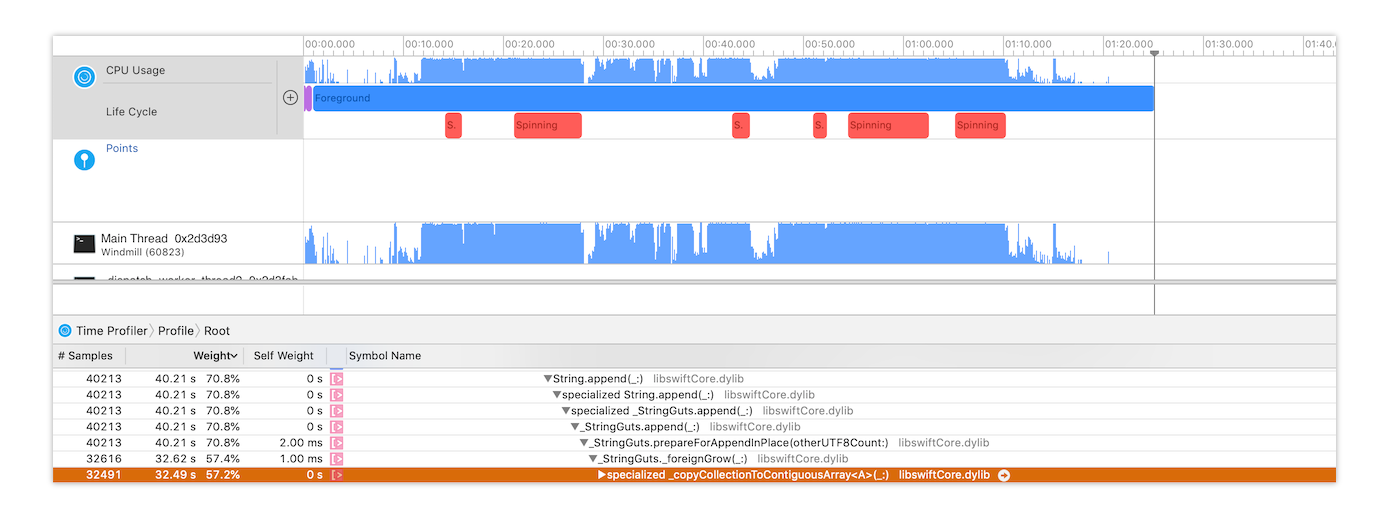
In other words. In Swift 5.0.x, any String.append(:) calls can potentially take a performance hit.
It’s a bridged NSString, so in the current model either reserveCapacity or the actual append will have to convert to a native Swift String, which will (in 5.0.x) incur O(n) CFStringGetCharacterAtIndex calls for some specific types of NSString.
— David Smith (@Catfish_Man) May 16, 2019
Similarly, any NSTextView.string.append(:) operations will also suffer.
This is what that performance hit looks like in my case, where a DispatchSourceRead is feeding a NSTextView every time there are bytes available to read.
let fileDescriptor = fileHandleForReading.fileDescriptor
let readSource = DispatchSource.makeReadSource(fileDescriptor: fileDescriptor, queue: self.queue)
readSource.setEventHandler { [weak readSource = readSource] in
guard let data = readSource?.data else {
return
}
let estimatedBytesAvailableToRead = Int(data)
//before: var buffer = [UInt8](repeating: 0, count: estimatedBytesAvailableToRead)
var buffer = [CChar](repeating: 0, count: estimatedBytesAvailableToRead)
let bytesRead = Darwin.read(fileDescriptor, &buffer, estimatedBytesAvailableToRead)
/*
Making sure that the buffer ends with a 0 since the bytes read are not guaranteed to.
`String(validatingUTF8:)` has a requirement that the "cString is A pointer to a null-terminated UTF-8 code sequence."
*/
buffer.append(0)
//https://twitter.com/Catfish_Man/status/1128934439096971264
guard bytesRead > 0, let availableString = String(validatingUTF8: buffer) else {
return
}
(completion ?? DispatchQueue.main).async {
self.output(part: availableString, count: availableString.utf8.count)
}
}
Use NSTextView.textStorage.append(:) and convert your String to an NSAttributedString using NSAttributedString(string:).
//before: textView.string.append(output)
textView.textStorage.append(NSAttributedString(string:output))This is what the performance looks like after the code change.
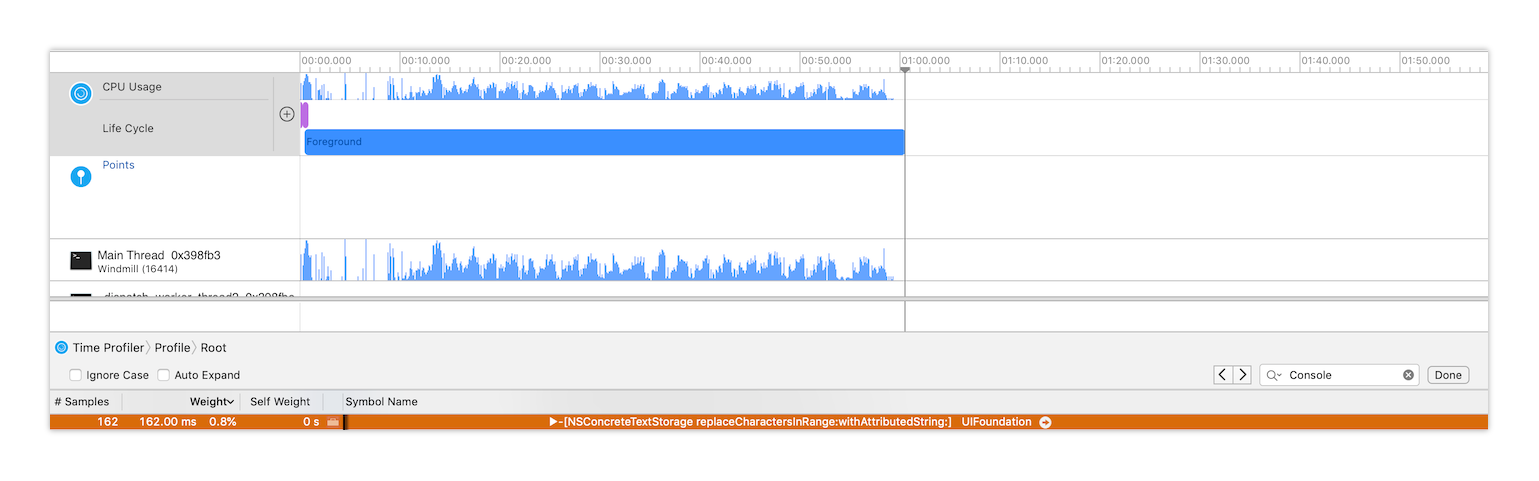
Couldn’t be more grateful for David Smith responding to my request as well as Marcin Krzyzanowski and Paul Goracke for nudging me to take a look at NSTextStorage.
This had the potential to be a huge time sink.
Swift 5.1 will be released sometime after March 18, 2019.
.-
Update
Started noticing some crashes on String(validatingUTF8:) with a Fatal error: UnsafeMutablePointer.initialize overlapping range when using it with an UnsafePointer<CChar>. Instead using the implementation as defined in the Discussion under the String documentation. Will report back.
Update 2
Re the Fatal error: UnsafeMutablePointer.initialize overlapping range. I hate having bad code around, even if it’s bad sample code. It’s been a learning experience for sure.
String(validatingUTF8:) has a requirement that the “cString is A pointer to a null-terminated UTF-8 code sequence.”. This code on the other hand makes no guarantees that this will be the case.
var buffer = [CChar](repeating: 0, count: estimatedBytesAvailableToRead)
let bytesRead = Darwin.read(fileDescriptor, &buffer, estimatedBytesAvailableToRead)Sure, it initialises the character array with 0 (i.e. null1) but read may fill that array and not end with a 0.
Back to the String(validatingUTF8:) initialiser. If you look at the source, it uses UTF8._nullCodeUnitOffset(in:) which “Is an equivalent of strlen for C-strings” which gets the length of the string (based on the presence of a null terminating character of course, we are going deep in C now). I was guessing that strlen takes a trip down memory lane© looking for that null terminating character and ends up way beyond an “acceptable” length. What is acceptable you say?
For that we have to take a look at the source code of UnsafePointer
public func initialize(from source: UnsafePointer<Pointee>, count: Int) {
_debugPrecondition(count >= 0,
"UnsafeMutablePointer.initialize with negative count")
_debugPrecondition(UnsafePointer(self) + count <= source || source + count <= UnsafePointer(self),
"UnsafeMutablePointer.initialize overlapping range")
Builtin.copyArray(
Pointee.self, self._rawValue, source._rawValue, count._builtinWordValue)
// This builtin is equivalent to:
// for i in 0..<count {
// (self + i).initialize(to: source[i])
// }
}So I decided to take the red pill, go down the rabbit hole and see for myself.
for i in 1...100_000 {
var buffer = [CChar](repeating: 1, count: 4096)
let string = OverlappingRange(validUTF8:buffer).string
print(string)
}Welcome to the Matrix2.-
“Remember…all I’m offering is the truth. Nothing more.”